


La bande passante utilisée dans la mémoire UMA pour la mémoire est restreinte car elle utilise un contrôleur de mémoire unique. L’avènement des machines NUMA a pour principal objectif d’améliorer la bande passante disponible de la mémoire en utilisant plusieurs contrôleurs de mémoire.
Tableau de comparaison
| Base de comparaison | UMA | NUMA |
|---|---|---|
| De base | Utilise un seul contrôleur de mémoire | Contrôleur de mémoire multiple |
| Type de bus utilisé | Simple, multiple et barre transversale. | Arbre et hiérarchique |
| Temps d'accès mémoire | Égal | Modifie en fonction de la distance du microprocesseur. |
| Convient à | Applications générales et à temps partagé | Applications en temps réel et critiques |
| La vitesse | Ralentissez | plus rapide |
| Bande passante | Limité | Plus que UMA. |
Définition de l'UMA
Le système UMA (Uniform Memory Access) est une architecture de mémoire partagée pour les multiprocesseurs. Dans ce modèle, une seule mémoire est utilisée, à laquelle tous les processeurs ont accès et qui présentent le système multiprocesseur à l'aide du réseau d'interconnexion. Chaque processeur a un temps d'accès en mémoire (latence) et une vitesse d'accès égaux. Il peut utiliser un commutateur à bus unique, à bus multiple ou à barre transversale. Comme il fournit un accès équilibré à la mémoire partagée, il est également connu sous le nom de système SMP (multi-processeur symétrique) .
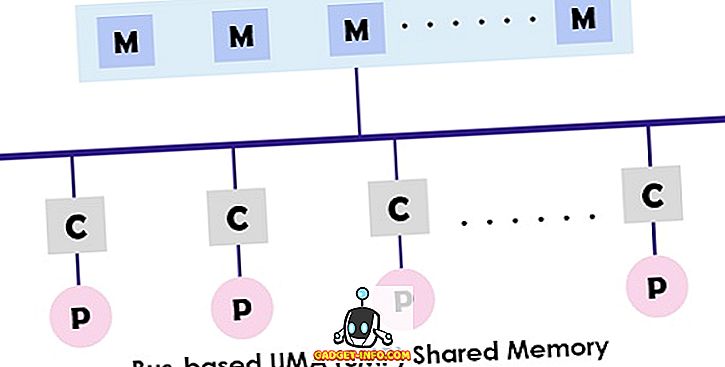
La conception typique du SMP est illustrée ci-dessus: chaque processeur est d'abord connecté au cache, puis le cache est lié au bus. Enfin, le bus est connecté à la mémoire. Cette architecture UMA réduit les conflits pour le bus en récupérant les instructions directement à partir du cache isolé individuel. Il fournit également une probabilité égale de lecture et d'écriture à chaque processeur. Les exemples typiques du modèle UMA sont les serveurs Sun Starfire, le serveur Compaq alpha et HP v series.
Définition de NUMA
NUMA (accès non uniforme à la mémoire) est également un modèle multiprocesseur dans lequel chaque processeur est connecté à la mémoire dédiée. Cependant, ces petites parties de la mémoire se combinent pour créer un seul espace d'adressage. Le point principal à considérer ici est que, contrairement à UMA, le temps d'accès de la mémoire dépend de la distance à laquelle le processeur est placé, ce qui signifie que le temps d'accès à la mémoire varie. Il permet d'accéder à n'importe quel emplacement de la mémoire en utilisant l'adresse physique.
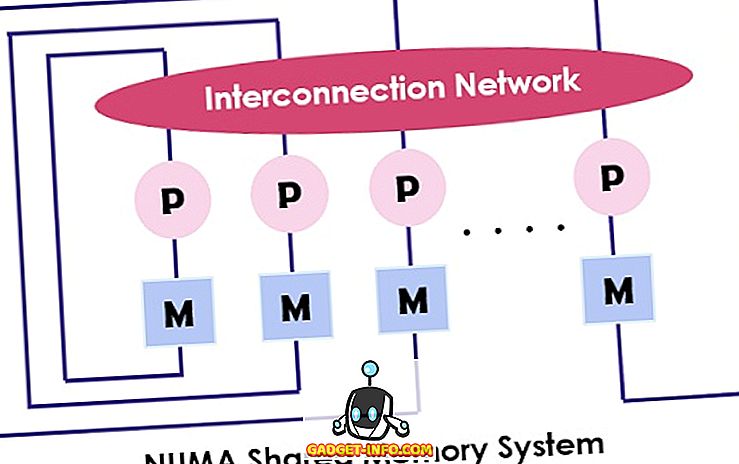
Comme mentionné ci-dessus, l'architecture NUMA est destinée à augmenter la bande passante disponible dans la mémoire et pour laquelle elle utilise plusieurs contrôleurs de mémoire. Il combine de nombreux cœurs de machine en « nœuds », chaque cœur étant doté d'un contrôleur de mémoire. Pour accéder à la mémoire locale d'une machine NUMA, le noyau récupère la mémoire gérée par le contrôleur de mémoire par son noeud. Alors que pour accéder à la mémoire distante qui est gérée par l'autre contrôleur de mémoire, le noyau envoie la demande de mémoire via les liens d'interconnexion.
L’architecture NUMA utilise l’arborescence et les réseaux de bus hiérarchiques pour interconnecter les blocs de mémoire et les processeurs. BBN, TC-2000, SGI Origin 3000, Cray sont quelques exemples d’architecture NUMA.
Différences clés entre UMA et NUMA
- Le modèle UMA (mémoire partagée) utilise un ou deux contrôleurs de mémoire. Par contre, NUMA peut avoir plusieurs contrôleurs de mémoire pour accéder à la mémoire.
- Les bus simples, multiples et crossbar sont utilisés dans l'architecture UMA. À l'inverse, NUMA utilise des types de bus et de connexions réseau hiérarchiques et arborescents.
- En UMA, le temps d'accès à la mémoire de chaque processeur est le même, alors que dans NUMA, le temps d'accès à la mémoire change en fonction de la distance entre la mémoire et le processeur.
- Les applications d'usage général et à temps partagé conviennent aux machines UMA. En revanche, l'application appropriée pour NUMA est une approche centrée en temps réel et critique.
- Les systèmes parallèles basés sur UMA fonctionnent plus lentement que les systèmes NUMA.
- En ce qui concerne la bande passante UMA, utilisez une bande passante limitée. Au contraire, NUMA a une bande passante supérieure à UMA.
Conclusion
L'architecture UMA fournit la même latence globale aux processeurs accédant à la mémoire. Ce n'est pas très utile lorsque la mémoire locale est accédée car la latence serait uniforme. D'autre part, dans NUMA, chaque processeur avait sa mémoire dédiée, ce qui éliminait la latence lors de l'accès à la mémoire locale. La latence change à mesure que la distance entre le processeur et la mémoire change (c'est-à-dire, Non uniforme). Toutefois, NUMA a amélioré les performances par rapport à l’architecture UMA.






